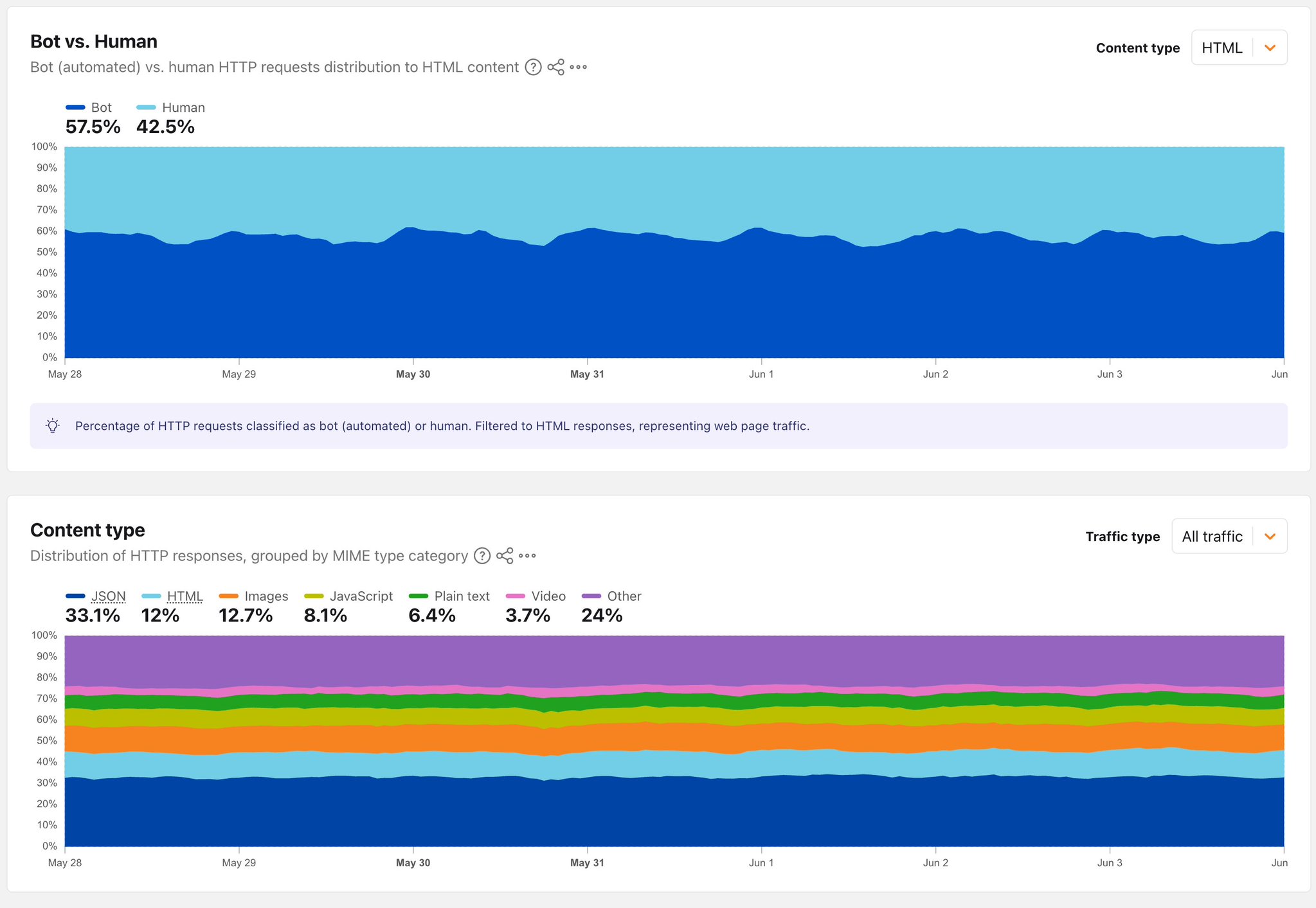
看网页的流量里,机器人首次超过人类(57.5%)
过去一周(5月28日—6月4日),全球 HTML 网页请求里机器人 57.5% > 真人 42.5%——互联网最像「人在看」的那部分,机器人已经是多数派。
昨天晚上,我一个朋友突然给我发了两张图。
两张图
我点开第一张,是 Cloudflare Radar 的一个数据截图。
过去一周(5 月 28 日—6 月 4 日),全球所有请求 HTML 网页 的流量里:机器人(爬虫、AI 抓取、自动化脚本等)占 57.5%,真人浏览器只占 42.5%。
也就是说,互联网上最像「人」在看的那部分内容,机器人已经是多数派了。
第一反应是卧槽。第二反应是打开第二张图。
那张图更狠:把全 HTTP 流量按返回内容分类——JSON 占 33.1%,排第一(API 标准格式,机器和机器对话);HTML 只有 12%(给人看的网页)。
两张图叠在一起的意思是:互联网流量的主体,已经不是「人打开浏览器看网页」了。
怎么说呢,作为一个在 AI 行业里泡了好几年的人,我一直以为 AI 是个工具,是给人用的。
但这两张图告诉我一件更基础的事:
- AI 不仅是工具了。
- AI 是互联网的主要居民。
- 而我们这些「人」,反而成了少数派。
那个陪了我们三十年的互联网,正在悄悄换主人。
Cloudflare Radar 是什么
简单说,Cloudflare 在全球有 330 多个城市的数据中心,托管着差不多 20% 的全球网站。所有经过他们的请求,他们都能看到元数据——谁在请求、请求什么资源、频率是多少。
Radar 是他们家免费公开的数据仪表盘。2025 年发布的 Year in Review 显示,他们家每秒要处理 8100 万次 HTTP 请求,峰值能到 1.29 亿次。
所以这两张图,基本可以代表整个互联网的现状:
- 第一张:人类 vs 机器人
- 第二张:按返回内容分类(大家平时不太看,我之前也没怎么注意,直到这次)
叠在一起看
你把两张图叠在一起,会发现一个反常识的事实:
HTML(给人看的网页)在整个互联网流量里只占 12%。
剩下的 88%,要么是机器人和机器之间的对话(JSON 占大头),要么是图片、视频、字体、CSS、JavaScript 等「网页附属品」,要么是监控、API、健康检查等基础设施流量。
给人看的内容本身,只占一成多一点。
这个事实,比 57.5% 还要命:
- 57.5% 说的是:在「人类看的内容」里,机器人比人类多。
- JSON 33.1% 说的是:在「整个互联网」里,机器对话比人看的内容还多。
后者才是真正的范式转移。
我们还在把 AI 当工具
我们现在很多人在用 AI,但方式往往还是:搜索引擎 + 聊天。
我们让 AI 写文案、答问题、生成图片——说到底,还是把 AI 当成更高级的工具。
但这两张图告诉我们:
- AI 已经不再只是工具。
- AI 是互联网的主要用户。
而我们的内容、思考、写下的每一个字,正在被这个主要用户大规模地、持续地、不被通知地吞噬。
AI 会读你的博客;读了之后,会把你消化成它自己的一部分,再吐给下一个用户。
Content Independence Day
说到这里,必须提一组我最近看到的数据。
2025 年 7 月 1 日,Cloudflare 干了一件大事。Matthew Prince 在博客上写了 《Content Independence Day》。里面有两个数字,让我盯着看了很久:
- 从 OpenAI 获得流量,比 10 年前通过 Google 获得流量,要难 750 倍。
- 从 Anthropic 获得流量,比 10 年前要难 30,000 倍。
你想想,30,000 倍。
也就是说:你今天辛辛苦苦写一篇文章,被 Anthropic 的爬虫抓过去、训练进模型、再吐给用户——回答里根本不会标出你。
十年前: 文章被 Google 索引,有人搜索点进来,你至少能拿到一次访问、一个广告展示、一个粉丝。
十年后: 你同样写一篇文章,可能被 AI 消费一万次,但回报是零。
为什么?因为 AI 时代,我们消费的不是原文,是衍生品。
Matthew Prince 有一句话,我翻来覆去看了几遍:
我们越来越不消费原文了,我们消费的是衍生品。
>
Increasingly we aren't consuming originals, we're consuming derivatives.
AI 把你的原文咀嚼一遍,吐出一个新回答——可能用了你的事实、数据、判断,但不会标出你。
你做了 100% 的工作,拿到了 0% 的回报。
同一天,Cloudflare 默认阻止所有 AI 爬虫,除非这些 AI 公司愿意为内容付费。
把这个时间点和这两张图放在一起看:
- 2025 年 7 月 1 日 — 互联网换主人的那一天。
- 2026 年 6 月初(过去这一周)— 主人把家搬得差不多了。
- JSON 33.1% > HTML 12% — 换家过程的数学证明。
好还是坏
好的方面: 知识传播效率被指数级放大。一个默默无闻的博主写的东西,可能被 AI 推荐给几千个原本永远不会看到他博客的人——这正是我们做内容的人最初想要的事。
坏的方面: 知识的原作者被彻底稀释。你的名字、语气、思考的痕迹,在这个过程中全被抹掉了。
更微妙的是:如果你写的内容正好是 AI 训练数据里没有的独特见解,AI 反而会模仿你——不会引用你,但输出会带上你的影子。
就是,你的灵魂被复制了一份,但你连被告知的权利都没有。
我也不知道这算是好事还是坏事。但有一点是确定的:互联网变了。
不是「AI 工具变强了」那种变化,是「互联网的主体变了」那种变化。
- 过去:上网的人。
- 现在:上网的人 + 上网的 AI。
- 再过几年:可能直接说上网的 AI,把人省略了。
这不是科幻。这是 JSON 33.1% > HTML 12% 背后已经发生的事实。
结语
借用 Matthew Prince 在 Content Independence Day 结尾的话:
The web is changing. Its business model will change.
互联网正在改变,它的商业模式也会改变。
但有一件事不会改变:值得被消费的好内容,永远是有价值的。
不管这个世界是被人类消费还是被 AI 消费,是被 HTML 承载还是被 JSON 包装——真正稀缺的东西,从来不会因为载体的变化而变得不稀缺。
时间。流逝的本身。